文字コードの変換で少しはまったので、備忘録としてメモしておく。
疑問
UnicodeのあはU+3042だが、これをutf-8で表すとなぜ0xe3 0x81 0x82 (e3 81 82)になるのか?
確認した結果
U+3042の0x30 0x42は2進数で表すと、下記のビット列になる
3 0 4 2
0011 0000 0100 0010
ところで、unicode -> utf-8への変換ルールは下記の通りになっている。
U+0000 - U+007F : 1byte ( 0xxxxxxx)
U+0080 - U+07FF : 2byte ( 110xxxxx, 10xxxxxx )
U+0800 - U+FFFF : 3byte ( 1110xxxx, 10xxxxxx, 10xxxxxx )
U+3042は3byte文字の範囲に入るので、1110xxxx, 10xxxxxx, 10xxxxxxの変換ルールになる。
これを、先ほど2進数に変換した"あ"に当てはめる。(ビットの切れ目が変わっていることに注意)
1110xxxx, 10xxxxxx, 10xxxxxx
0011 000001 000010
なので、下記のビット列になる。
11100011, 10000001, 10000010
これを16進数に戻すと以下の形になる。
1110 0011, 1000 0001, 1000 0010
e 3 8 1 8 2
なので、あのU+3042は、utf-8のエンコードで0xe38182になる。
Amazonでおトクに買い物する方法
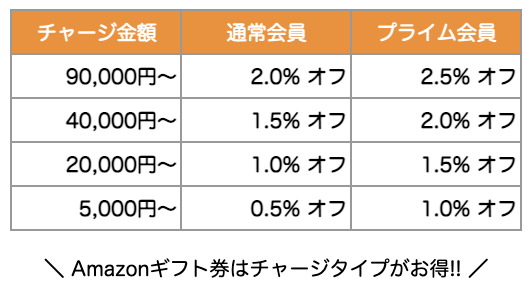

Amazonは買いもの前にAmazonギフト券をチャージしてポイントをゲットしないと損!
AmazonチャージでポイントGET
Amazonは買いもの前にAmazonギフト券をチャージしてポイントをゲットしないと損!
こちらもおススメ
